Connection to Multimodal Learning
Autoencoders are crucial precursors and components in multimodal systems.
- Representation Learning: Core task in ML. AEs learn compressed, meaningful representations (the *latent code*) from input data (like images).
- Shared Latent Spaces: In multimodal learning, variants of AEs help map data from different modalities (e.g., images and text) into a common latent space.
- Cross-Modal Generation: Decoding from this shared space can allow generating one modality from another (e.g., generating image captions).
- Dimensionality Reduction: Essential for handling high-dimensional multimodal data efficiently.

(Generic diagram showing modality mapping via latent space)
This project focuses on visualizing the *unimodal* representation learning aspect, a building block for more complex multimodal architectures.
Project Core: Configuration & Training
Configuration
- Select Dataset (MNIST/Fashion-MNIST)
- Define Bottleneck Size (e.g., 2x2, 3x3)
- Set Filter Counts for Conv Layers
- Specify Number of Training Epochs
Real-time Training
- Initiate training via API call.
- Backend trains model in background thread.
- Frontend polls for status updates.
- Live Training/Validation Loss chart (Chart.js).
- Clear status messages (Epoch progress, final loss).
(Screenshot of Config Area & Chart)
Project Core: Interactive Inference (1/2)
Input
- Draw directly on the canvas.
- Upload custom images (PNG/JPG).
- Image is preprocessed (28x28 grayscale, normalized).
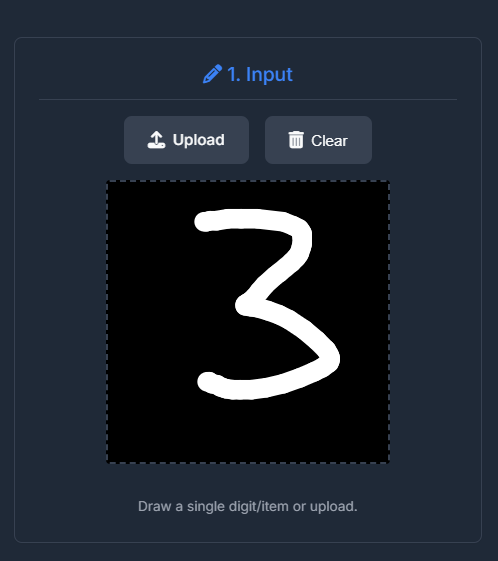
(Screenshot of Canvas Input Area)
Encoder Visualization
- Input image passed through the trained encoder.
- Visualize activation maps from each Conv layer.
- Shows features extracted at different stages (edges, patterns).
- Uses colormaps (like Viridis) for clarity.
- Hover to zoom on individual feature maps.

(Screenshot of Encoder Activations)
Project Core: Interactive Inference (2/2)
Bottleneck
- View the compressed latent vector values.
- **Crucially:** Manipulate values using sliders.
- Observe real-time changes in the decoded output.
- Provides intuition for the latent space structure.
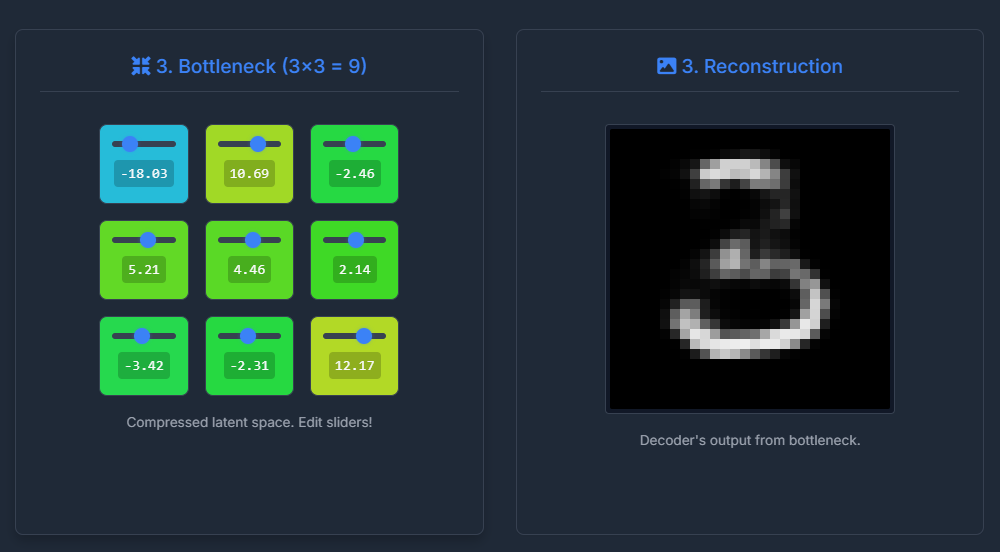
(Screenshot of Bottleneck Grid and Output of Decoder)
Decoder & Output
- Latent vector (original or modified) fed to decoder.
- Visualize activations from ConvTranspose layers.
- Shows how features are gradually reconstructed.
- View the final 28x28 reconstructed image.
- Compare input vs. output.

(Screenshot of Decoder Activations)